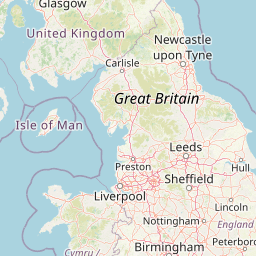
I’m working on a few ideas about Motorway Service Stations in the UK, or more specifically the mainland of Great Britain (England, Scotland and Wales). However, I was surprised to discover there weren’t any well structured datasets. There is an incrediblewebsite available at www.motorwayservices.info - I thoroughly recommend a visit.
For very sensible reasons they don’t allow data to be scraped (we can’t use {rvest}), so I’ve manually downloaded all 107 web pages for the motorway service stations and have them in this folder:
# A tibble: 18 × 2
property value
<chr> <chr>
1 Motorway "M74"
2 Where "at J13"
3 County "South Lanarkshire"
4 Postcode "ML12 6RG"
5 Type "Single site, used by traffic in both directi…
6 Operator "Welcome Break"
7 Contact Phone "01864 502637"
8 Eat-In Food "Starbucks, Papa John's, Burger King, Dunkin'…
9 Takeaway Food / General "Retail Shop"
10 Other Non-Food Shops "WH Smith"
11 Picnic Area "yes"
12 Cash Machines in main building "Yes (transaction charge applies)"
13 Parking Charges "Cars free for the first 2 hours then £5 for …
14 Other Facilities/Information "GameZone, Tourist Information, BT Openzone"
15 Motel "Days Inn Hotel Abington (Glasgow)"
16 Fuel Brand "Shell"
17 LPG available "Yes"
18 Cash Machines at fuel station "Yes (transaction charge applies)"
Okay! That’s enough processing to a function I can use to read in all of the data:
# A tibble: 19 × 3
property value service_station
<chr> <chr> <chr>
1 Motorway A1(M) Baldock Servic…
2 Where at J10 and from A507 Baldock Servic…
3 County Hertfordshire Baldock Servic…
4 Postcode SG7 5TR Baldock Servic…
5 Type Single site, used by traffic … Baldock Servic…
6 Operator Extra MSA Baldock Servic…
7 Contact Phone 01494 678876 Baldock Servic…
8 Eat-In Food KFC, Le Petit Four, McDonalds… Baldock Servic…
9 Takeaway Food / General M&S Simply Food, WH Smith (wi… Baldock Servic…
10 Picnic Area yes Baldock Servic…
11 Children's Playground Yes Baldock Servic…
12 Cash Machines in main building Yes (transaction charge appli… Baldock Servic…
13 Parking Charges First two hours free for all … Baldock Servic…
14 Other Facilities/Information Fast Food & Bakeries and Conv… Baldock Servic…
15 Motel Days Inn Stevenage North Baldock Servic…
16 Fuel Brand Shell Baldock Servic…
17 LPG available Yes Baldock Servic…
18 Cash Machines at fuel station Yes (free) Baldock Servic…
19 Other Facilities/Information Costa Express & Deli2Go avail… Baldock Servic…
Some service stations come in pairs (dual-site service areas or twin sites) that are split by the motorway and yet still have the same name. For instance, Rownhams Services has a McDonalds when accessed westbound but not eastbound. If you looked at a map of the services it appears that they’re not connected (that’s an overhead sign not a footbridge!).
The Eat-In variable is the most complicated, interesting and ripe for visualisation. So let’s treat it separately. First we’ll identify our twin-site restaurants:
Code
data_raw_eat_in <- data_raw_services %>%filter(property =="Eat-In Food") %>%mutate(directional =str_detect(value,"Northbound|Eastbound"))data_raw_directional_eat <- data_raw_eat_in %>%filter(directional ==TRUE) %>%mutate(direction =case_when(str_detect(value, "Northbound") ~"Northbound|Southbound",str_detect(value, "Eastbound") ~"Eastbound|Westbound" )) %>%separate_longer_delim(direction,delim ="|") %>%mutate(value =case_when( direction =="Northbound"~str_extract(value,"(?<=Northbound: ).*(?=Southbound)"), direction =="Southbound"~str_extract(value, "(?<=Southbound).*"), direction =="Eastbound"~str_extract(value,"(?<=Eastbound: ).*(?=Westbound)"), direction =="Westbound"~str_extract(value,"(?<=Westbound: ).*") )) data_raw_directional_eat
Frustratingly, Strensham Services has an extra little bit of data about Subway being in the Northbound Forecourt. That’ll need manual removal. But other than that I think we end up with fairly well structured data for the eat-in component that we can begin to clean up.
There are lots of alternative spellings in the data, here’s a case_when to grab them all. At some point in the future it would be interesting to see if edit distances could help, but for now let’s concentrate on getting a useful dataset.
Now… I’m a little unsure about what to do with the “Takeaway Food / General” property as it also contains information about where we can get food but for the 6 twin stations the direction isn’t provided. Let’s deal with the directionless other retailers now:
# A tibble: 650 × 8
retailer service_station direction is_food_retailer is_restaurant is_takeaway
<chr> <chr> <chr> <lgl> <lgl> <lgl>
1 Starbuc… Abington Servi… Directio… TRUE NA TRUE
2 Papa Jo… Abington Servi… Directio… TRUE TRUE TRUE
3 Burger … Abington Servi… Directio… TRUE TRUE TRUE
4 Dunkin'… Abington Servi… Directio… TRUE FALSE TRUE
5 Harry R… Abington Servi… Directio… TRUE TRUE TRUE
6 Costa Annandale Wate… Directio… TRUE FALSE TRUE
7 Restbite Annandale Wate… Directio… TRUE NA NA
8 The Bur… Annandale Wate… Directio… TRUE TRUE TRUE
9 KFC Baldock Servic… Directio… TRUE TRUE TRUE
10 Le Peti… Baldock Servic… Directio… TRUE FALSE TRUE
# ℹ 640 more rows
# ℹ 2 more variables: is_prepared_food_only <lgl>, is_coffee_shop <lgl>
Non-food information
The non-food information is so much easier to deal with. Because I want to create an {sf} object and potentially support exporting as ESRI shapefiles let’s make sure our colnanes have a maximum of 10 characters.
There are some services like Gloucester Services M5 that appear as two distinct rows but they still pass is_single == FALSE. Let’s identify these services and mark them in the dataset as pair_name.
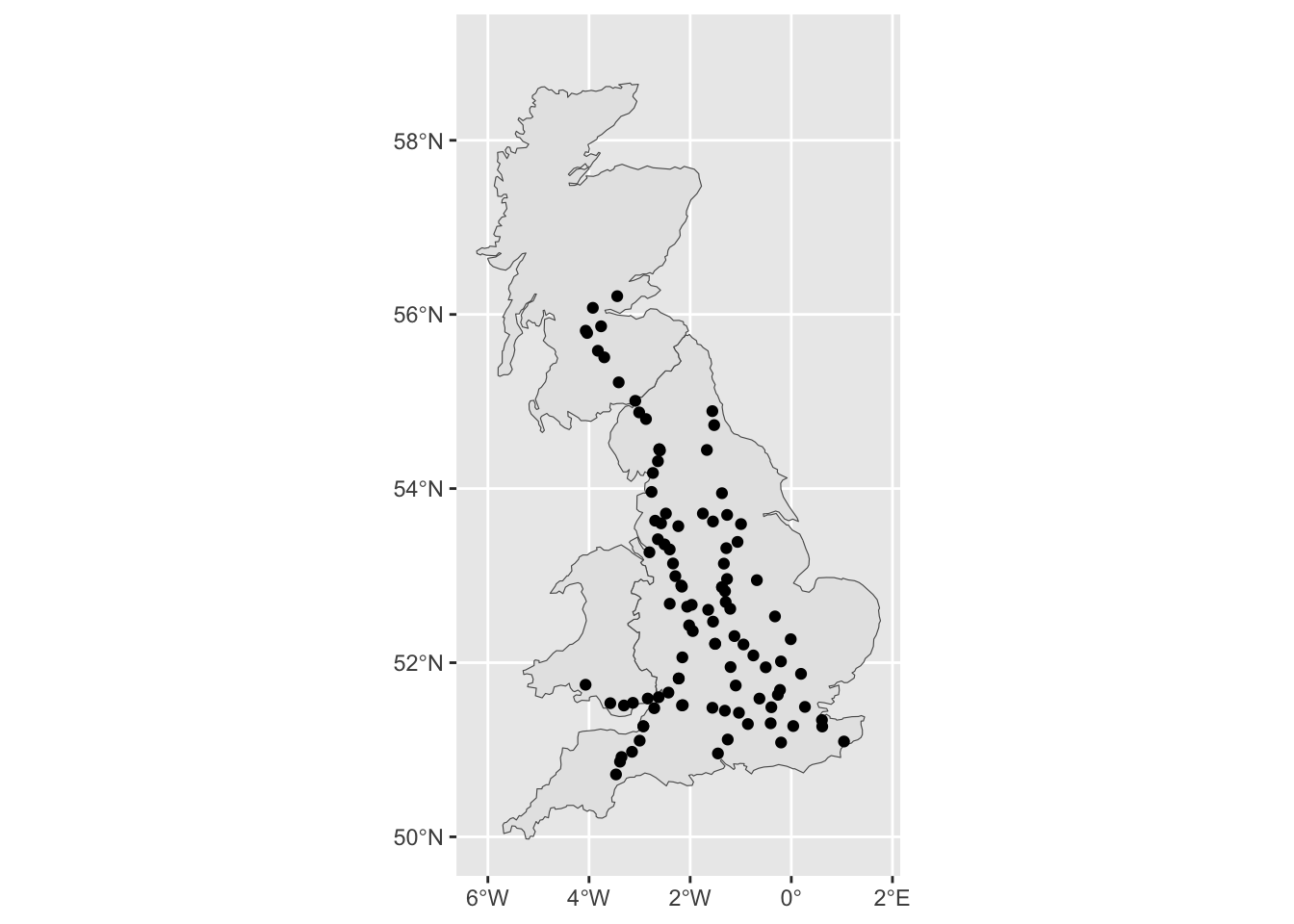
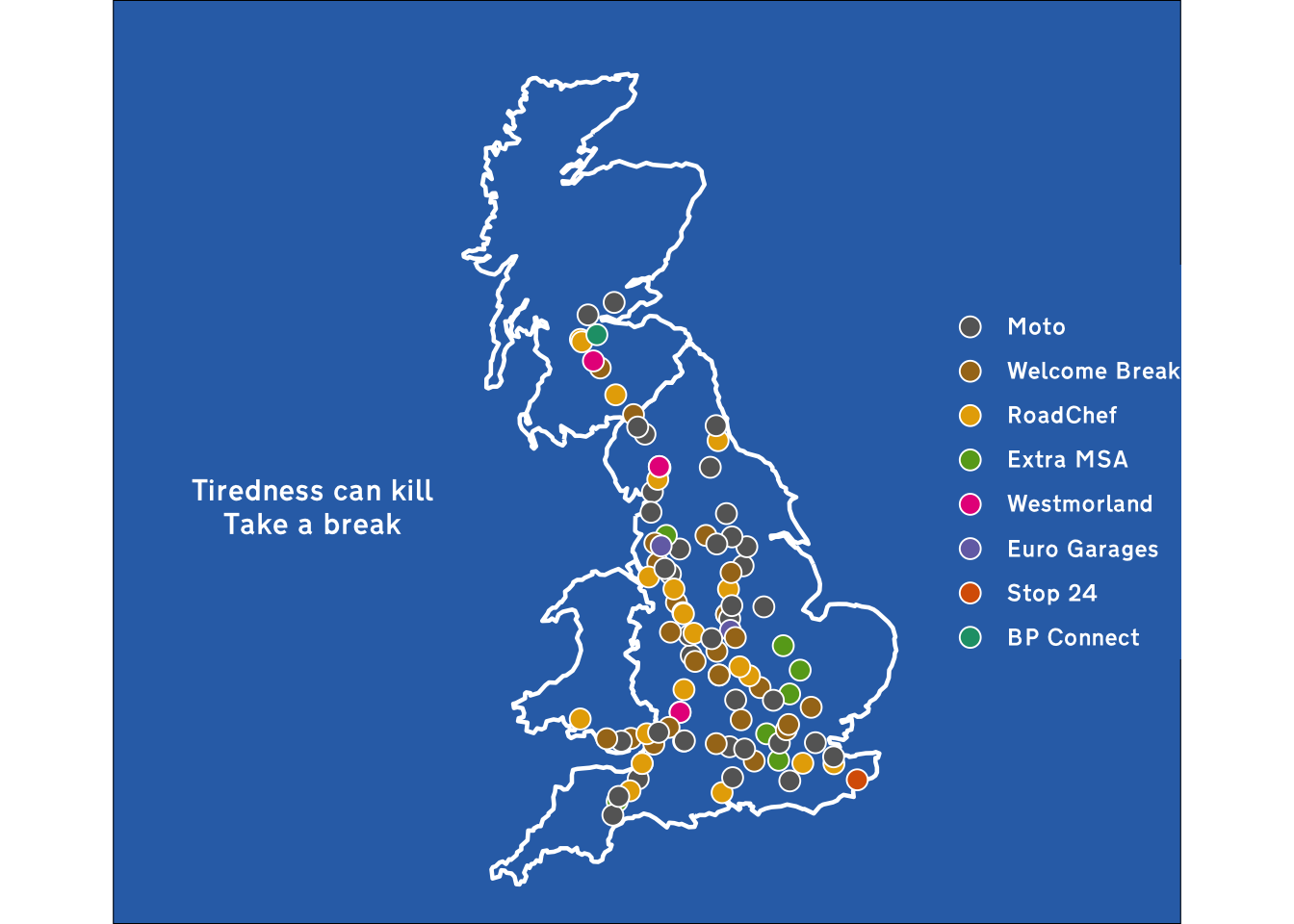
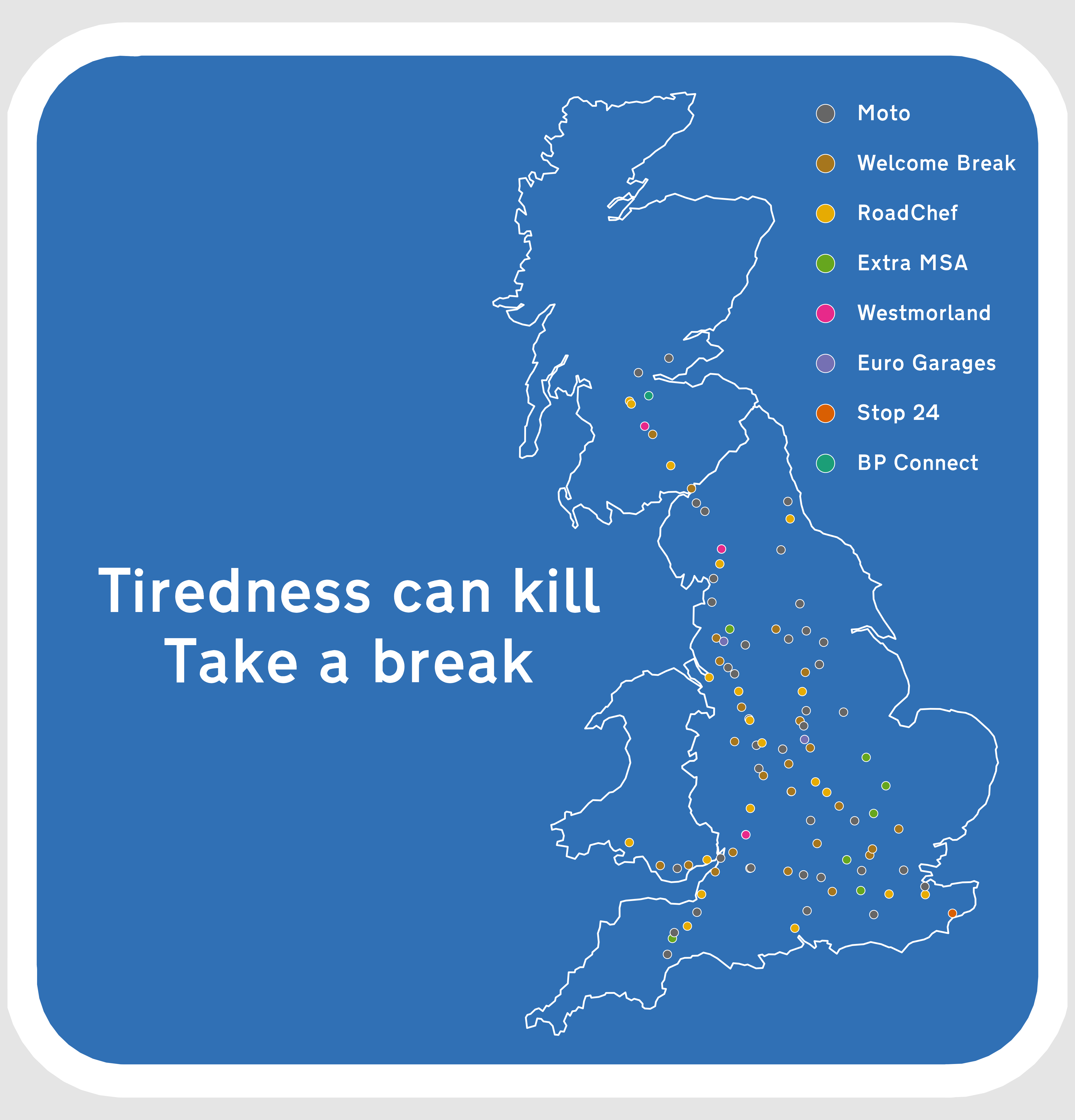
I’ve gone and got the coords from Google Maps and stored them in an Excel file (because I’m not perfect). Here’s a very quick interactive {leaflet} map showing where they are:
I want to make sure we’re not over counting operators due to pair sites! So let’s make some explicit counts.
n_named_sites_all: How many uniquely named sites are there across Great Britian? Gloucester Northbound Services M5 and Gloucester Southbound Services M5 are distinctly named, but the Birch Services M62 is listed once despite being a twinned site.
n_named_sites_mainland: same as above but discounting services in Ireland
n_named_sites_ireland: only counts uniquely named services in Ireland
n_single_sites: How many sites are accessible by traffic in both directions
n_twins: How many sites are twinned, two locations on each side of the motorway with or without a walkway between them
n_pairs: How many sites have paired names, eg Gloucester Northbound Services M5 and Gloucester Southbound Services M5
I’d really love this dataset to become a Tidy Tuesday dataset! So while writing this post I’ve created a fork of the repo. If my eventual pull request gets accepted we’d be able to pull the data from the official TidyTuesday repo, but until then it’s available as follows
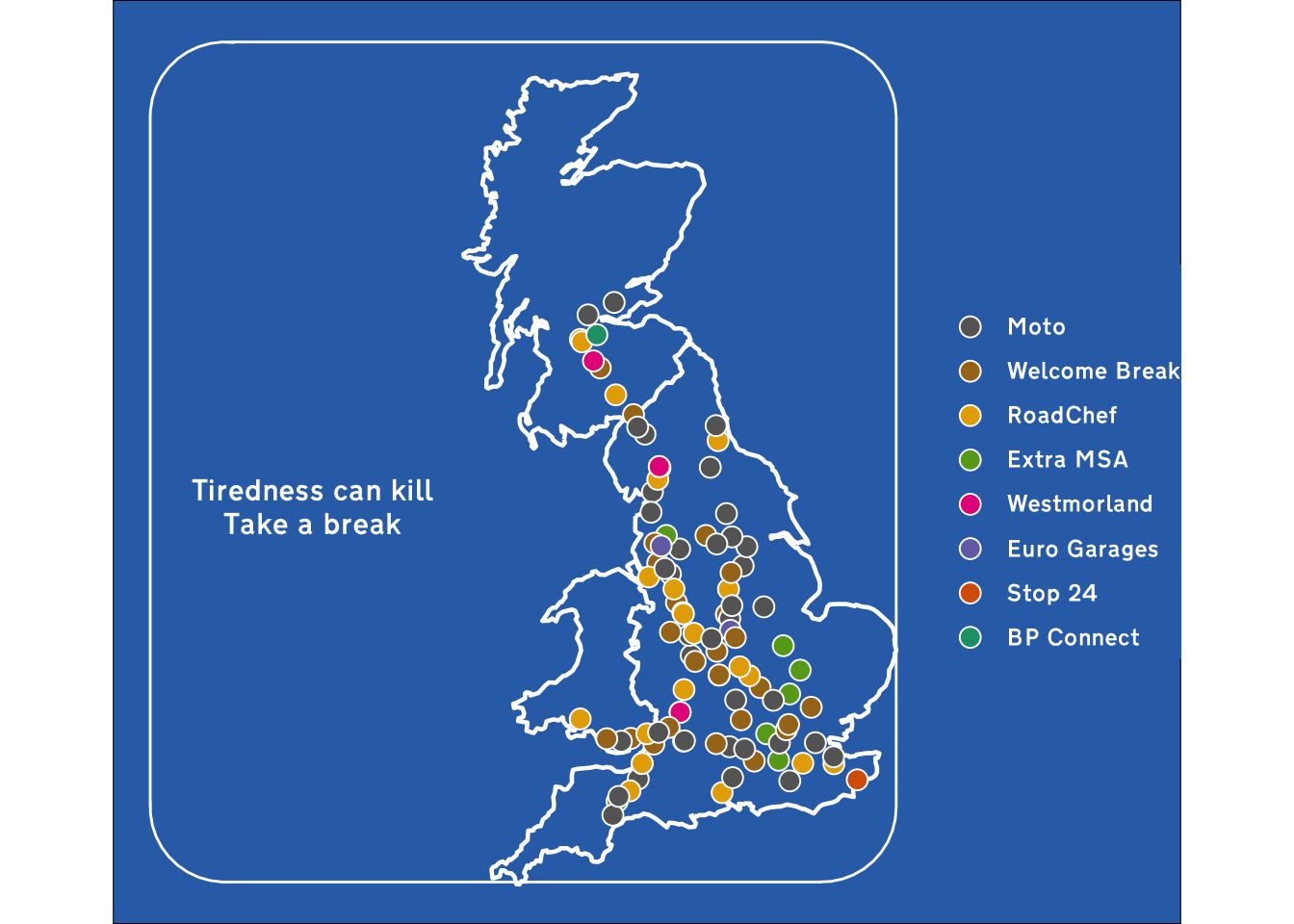
At some point it could be fun to take all of this and convert it into a {ggplot2} theme - but that’s a lot of work. I want to focus on getting that nice round white border on my chart. That’s more difficult than I originally thought, there are two pathways:
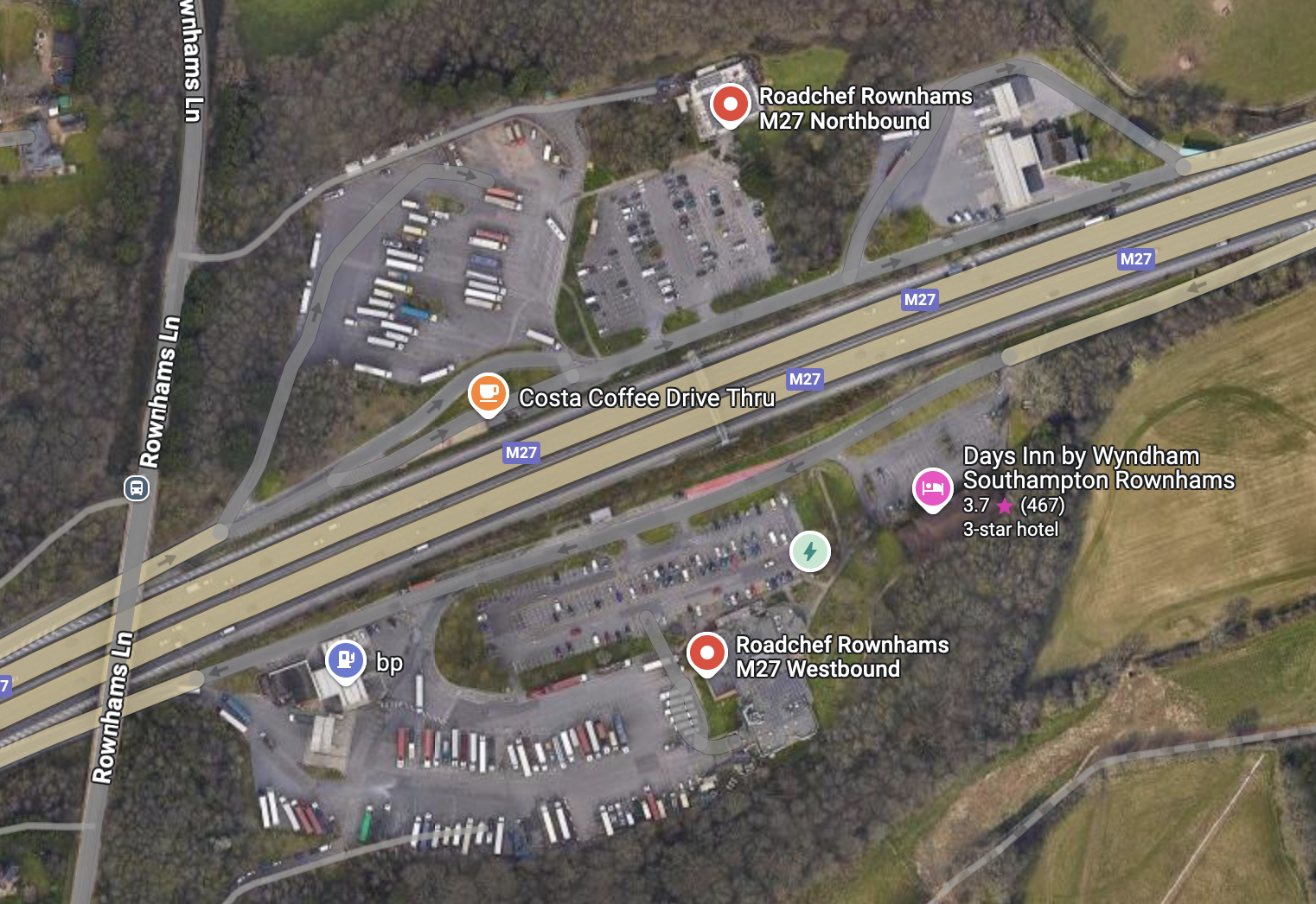 But they are! There’s a subway connecting them, which is
But they are! There’s a subway connecting them, which is